一、前言
K-means算法是一种分类算法,属于非监督式学习,以下对其原理分析和实现
- 系统:win10
- 环境:python3.7
二、K-means原理说明
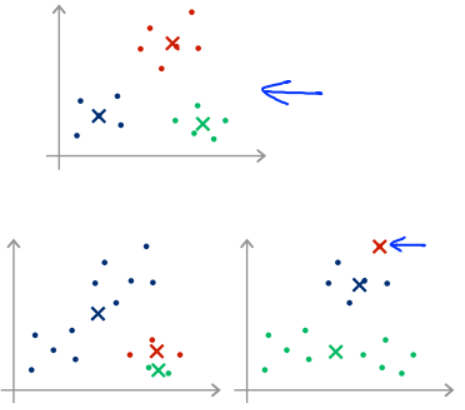
如下图所示,我们可以很清楚的分辨出这里分为4类,并且可以确定这4类的位置,但是电脑需要如何分辨出来呢?
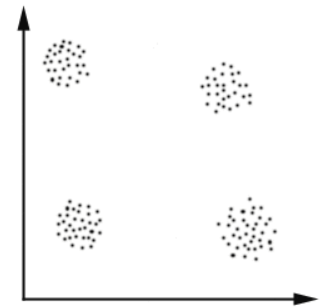
- 在图中随机定义4个点A、B、C、D,表示分类(也就是事先知道分为4类)
- 计算图中每个点和这4个随机点的距离(假设有n个点,需要计算4*n次),每个点选取和他最近的点确定该点属于那个分类。
- 每个分类(A、B、C、D),根据选择它的数据点的位置,重新调整自己的坐标。
- 重复上面2~3的过程,直道不再出现数据点变化分类。
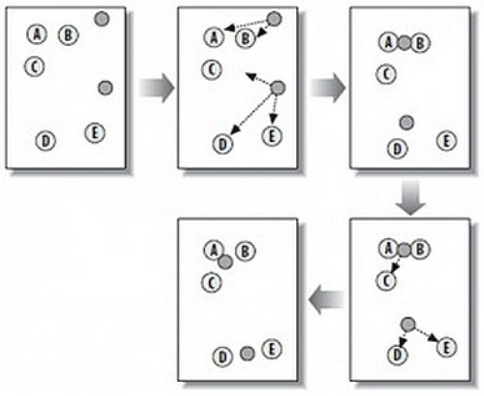
- 上述过程大致可以用下图描述:
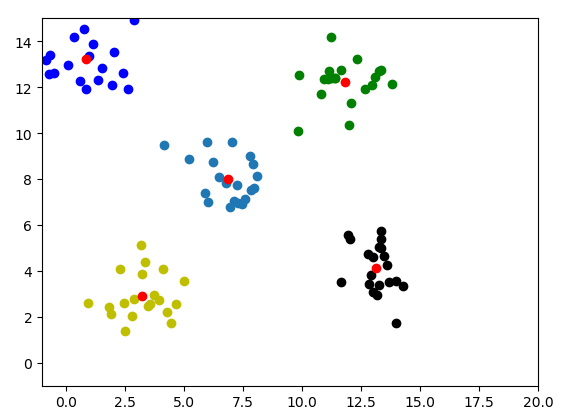
使用第四节的代码进行测试,可以得到不错的效果,图片如下:
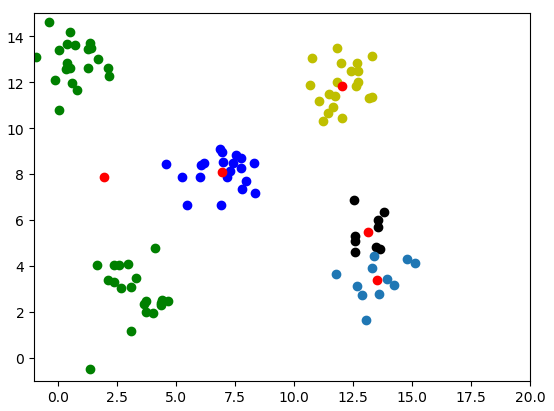
但是他的结果会波动,不太确定,输出结果和质点的初始化有关,有时候会出现以下结果:
三、二分K-Mean原理说明
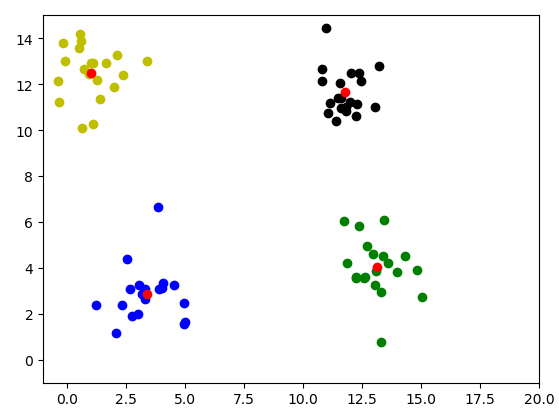
根据上面K-Mean所描述的原理,由于是随机定义的中心分类,不同的随机结果很容易导致不同的结果出现,比如几个中心点移动到同一堆数据中(如下图所示),容易陷入局部最优。解决方法可以通过定义多个中心点来达到,但还是存在了一些不稳定的情况。这里介绍K-Mean的二分法。
对K-means的代码进行分析,可以看到,当只分两类的时候才会得到稳定的结果。所以先把原来的质点分为2类,然后对这两类在进行划分(选取效果最好的一类进行再次划分),迭代多次后,可以得到分类的点。对4类进行分类结果如下图:
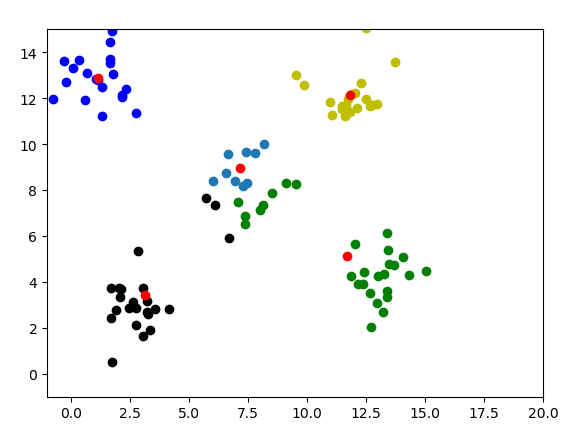
结果很完美,但是由于其是KMeans的改进版,所以缺点都差不多。下面对5组数据点进行分类,可以看到有明显的缺陷,中间的一组划分明显不好,结果如下图所示:
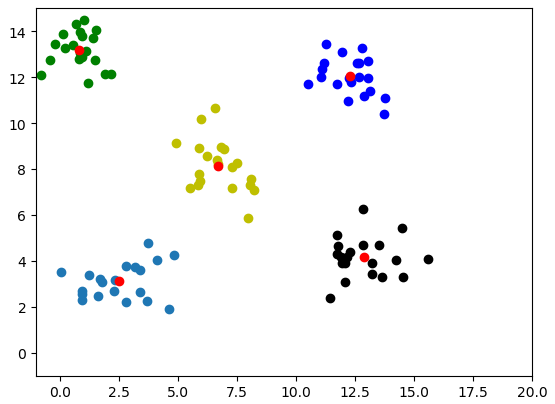
解决方法是在二分Kmeans结束后,再使用普通kmeans处理一次,重新运行后结果如下:
四、K-mean代码实现
1 | # -*- coding: utf-8 -*- |
五、二分K-mean代码实现
1 | # -*- coding: utf-8 -*- |
