一、神经网络第一课
- 神经网络分类
- 激励函数
- 过拟合
- 网络搭建
- 数据集搭建
- 开始训练
- 调整参数
注:没有我讲 是很难看懂滴
二、神经网络分类
从代码的角度来讲,主要分为2类,线性网络和卷积网络。
2.1 线性网络
线性网络大致如下图,对一维数据进行操作
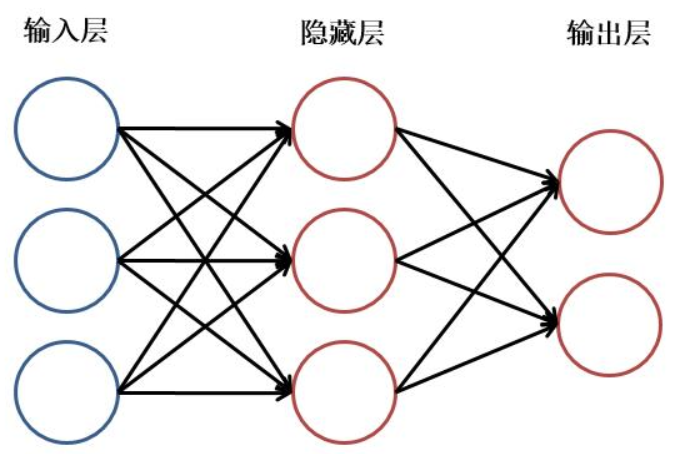
- 神经元:激励函数,一般为relu、sigmod等,也可以没有
- 黑色的线:$y = wx + b$,在代码中b(bias)默认有,可以通过设置取消
建立线性网络格式如下,这种建立只是为了把网络搭建起来,具体的激励还得另外写
1 | nn.Linear(inputChannel, outputChannel,bias = True) |
2.2 卷积网络
卷积网络大致如下,是对二维数据进行操作,如图片
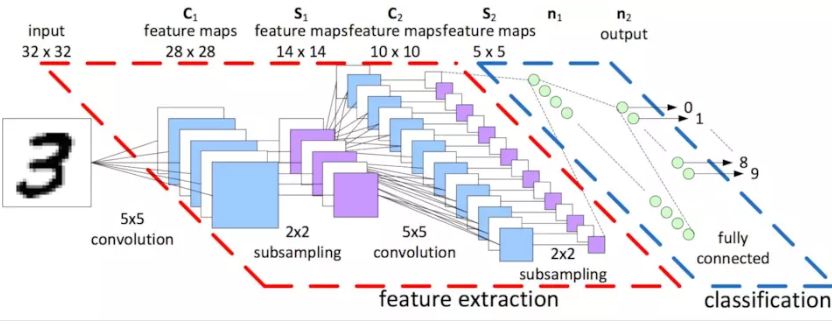
- 神经元:激励函数
- 黑色的线:如上线性网络一样
- 建立卷积网络代码如下:
1 | nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding,bias=bias) |
三、激励函数
如果没有激励函数的话,那么层和层之间的传递关系式为:$y = wx + b$,可以看到这个为一次函数。一次函数的缺点很明显,值域无穷,反正在一些对值域有要求的情况下就会不好。所以后面提出了sigmod,tanh等激励函数。
这些常用的激励函数见下链接:点我
四、过拟合
简而言之,学习能力太强,把数据全部记住了,以后除了训练数据能输出正确结果,其他的都不认。
造成原因:数据集太少(主要原因),学习迭代次数过多。解决方法,使用dropout函数,在每次学习的时候使一些神经元的数据失效,一般放在最后一层网络层来用。
略
五、网络搭建
网络搭建是整个神经网络代码中最简单的部分,下面用数据对一次函数拟合,先给出拟合完成的图片。如图所示,红色为拟合结果,蓝色为数据。
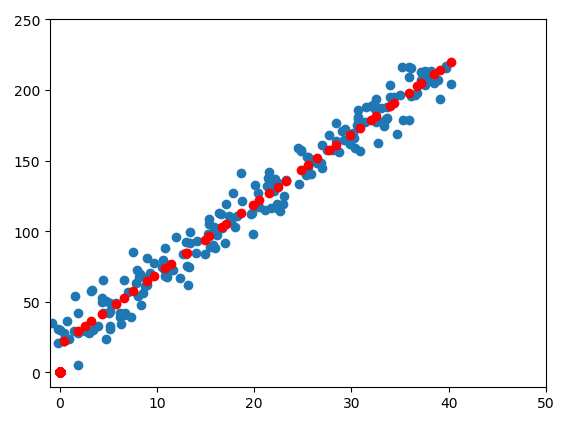
注:最下面那个(0,0,)点是绘图程序写的不严谨出现的,和网络输出无关
设计思路非常简单,使用简单的一个神经元就好
1 | class net(nn.Module): |
对这个网络建立的细节进行一些讲解和注意事项。此时只学习$w,b$
六、数据集搭建
这是整个神经网络中最繁琐的地方,大部分时候需要自己搜集,如果是图片,动辄就是几万张。但是这里拟合的话,数据就可以模拟生成。
1 | def generateData(k, b): |
这里使用在确定的一次函数,通过正太分布的的随机值,参数随机坐标。结果如图所示:
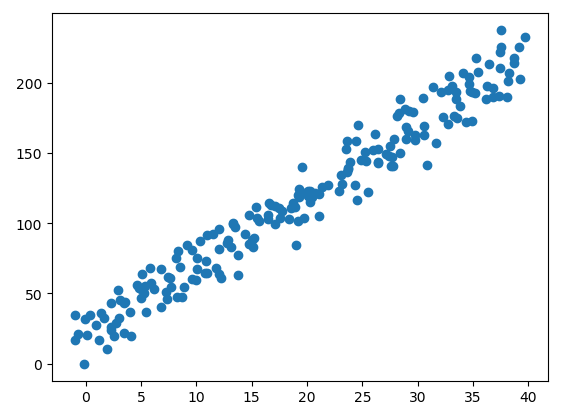
将生成的数据打印出来看
七、开始训练
1 | model = net() |
八、调试
如果参数不对或者不合适的话,就会出现nan、或者拟合的一次函数的偏置b貌似为0,此时需要进行调试,查看那里出现了问题,打印网络节点参数(一个网络可以这么调试,几万个我就不知道了)
1 | for name, param in model.named_parameters(): |
通过参数可以看到,偏置b在变动,只不过变动的非常缓慢,没有w变动的快,此时可以通过调整b的学习速率
九、调整学习速率
1 | optimizer = torch.optim.SGD([ |
这样就可以了,但是这样如果面对很多层网络,手写肯定不是办法,下面采用一个函数来解决
1 | def setparamsLr(model,lr): |
十、数据集操作(补充,不重要)
如果想要对数据集进行一些特殊的操作,比如一次取出多组数据,打乱数据集呢。这里就需要使用数据集对应的库。先给个可以单独运行的例子
1 | from torch.utils import data |
细致修改有些复杂,后面再说
十一、loss函数自定义
如果我不是输出预测值,而是要求w,b的具体值,改怎么做。
此时就是多项式拟合,拟合系数,可以参考百度教程,此时就需要自定义loss,因为网络输出的结果经过一定计算才可以得到具体损失。
