一、环境
- 系统:win10
- 语言:python3.7
- 算法基础:动态规划
二、原理说明
2.1 算法目的
根据不同数据被索引的次数,对数据构建二叉树。比如在输入法中,有些常用词汇就应该放在树的前面,可以更快的被索引到。数据存放的位置根据每个数据被索引的概率放置,要求平均查找次数最小。例如:
对于以下数据:
1 | arr = [4,2,5,1,7,3] |
其被对应被索引的概率为:
1 | p = [0.1, 0.05, 0.2, 0.25, 0.35, 0.05] |
构建如下二叉图:
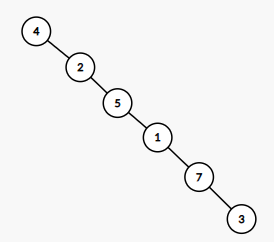
其平均搜索次数为:
如果构建如下二叉图:
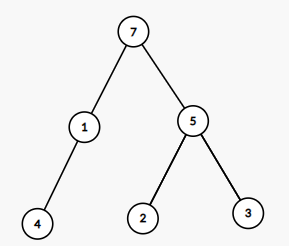
其平均搜索次数为:
所以,合理的摆放数据位置,可以大大的提高搜索效率
2.2 公式表达
符号说明:
- $k$:第$k$个位置的数据索引
- $p_k$:表示第$k$个数据被索引到的概率
- $T(i,j)$:是由$\{r_i,…,r_j\}$构成的二叉树,其中$i<j$。
- $C(i,j)$:是由$\{r_i,…,r_j\}$构成的二叉树的平均搜索次数。
假设在$\{r_i,…,r_j\}$中,选择$r_k$作为二叉查找树的根节点:则其平均搜索次数可以表示为:
对上式进行化简:
通过以上推导,已经得到了函数递推式(动态规划算法必备),接下来需要初始化(使用别人的图):
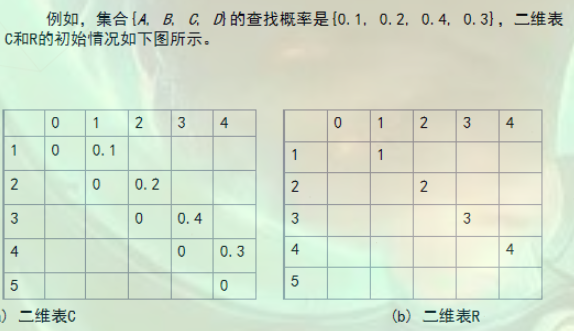
初始化之后,对每个位置的书进行推导:
以此为例子,一直推导计算到$C(1,4)$最优计算次数。结果为(别人的图):
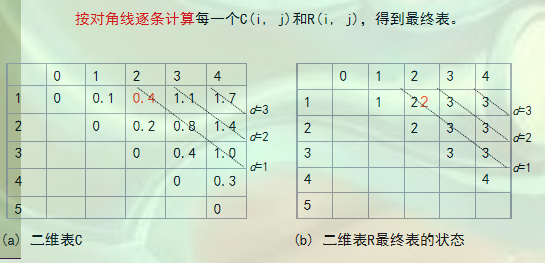
观察这个表,可知可知左边的表的第一行的第四列就是我们要求的最优平均比较次数,而右边的表我们可以知道在c(i ,j)得到最优解,即平均查找次数最小的根节点,比如一共四个节点,则我们从右边的R(1,4)的值即3是这四个节点构成的树的根节点。则树的左子树变为c(1,2),他的根节点是r(1,2)=2,然后2又有左节点1,而4则是3的右节点。则树的样子便出来了。
2.3 代码实现
(当然也是别人的)
1 |
|
参考文献
1. 最优二叉查找树_动态规划 ↩
