一、tf.nn.softmax
1.1 含义
Softmax简单的说就是把一个N*1的向量归一化为(0,1)之间的值,由于其中采用指数运算,使得向量中数值较大的量特征更加明显
1 | import tensorflow as tf |
1.2 计算公式
对于输入的一维向量(有N个数据),采用以下公式进行归一化:
如果输入多维是什么情况,如上述代码结果所示,按照每一维进行单独运算。
1.3 优点
- 优点一:输出值加起来为1,有点类似于概率,结果简单直观
- 优点二:大多数代价函数使用$C = - \sum_i y_k ln y_i$,其中目标$y_k$为1,其余的$y_k$为0。所以对于代价函数,只有当概率接近于1时,代价函数才接近于0。
- 优点三:求导方便(具体推导,可以查其他博客) 1
1.4 使用方法
一般放在全连接层到输出层,方便最后计算代价函数使用
二、tf.nn.dropout
2.1 含义
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
- 容易过拟合
- 费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。过程其实很简单,如下两幅图所示,对中间层进行dropout,可以看到使得一般的神经元失效。
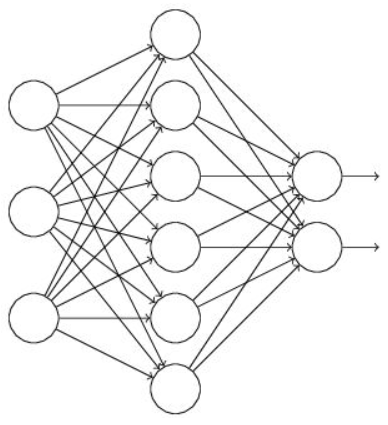
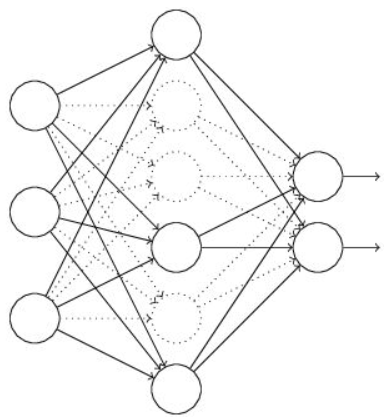
注意这里并不是却掉了神经元,而是把这个位置的神经元的输出值置0。
2.2 函数功能
1 | dropout(x, keep_prob=None, noise_shape=None, seed=None, name=None, |
- x:一个张量
- keep_prob:神经元被选中的概率,选中则置零
- noise_shape: 一个1维的int32张量,代表了随机产生“保留/丢弃”标志的shape。
- name:操作名字
参考代码
1 | with tf.Session() as sess: |
2.3 优缺点
- 优点:防止过拟合
- 缺点:学习速度下降
三、tf.nn.relu
3.1 含义
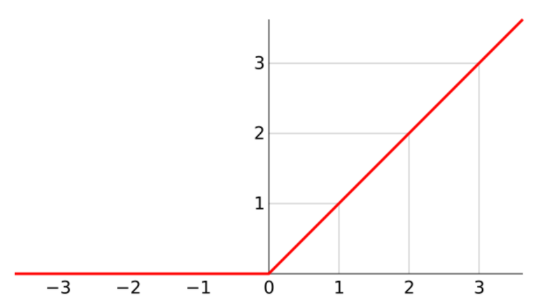
这是一个线性整流函数(修正线性单元),通常情况下线性整流函数是一个斜坡函数,即:
函数图像如下:
3.2 函数功能
输入小于0的数置0,大于0的数不变。输入参数为一个张量2,示例代码如下:
1 | import tensorflow as tf |
3.3 相似函数3
- PReLU
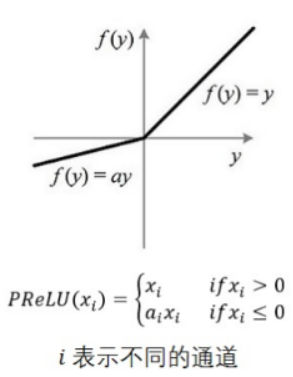
其中$a_i$是可以学习的,TensorFlow对应于:(没有找到) - LReLU
图片和PReLU一样,但是$a_i$是固定值,TensorFlow对应于:tf.nn.leaky_relu(features, alpha=0.2, name=None)
3.4 Relu和sigmoid、tanh的异同
参考文章4
四、tf.nn.conv2d
4.1 含义
是TensorFlow里面实现卷积的函数
4.2 函数功能
1 | tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None) |
第一个参数input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一。batch参数的存在表示可以同时卷积多个图片,并且互不干扰。
第二个参数filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
第三个参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
第四个参数padding:string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式(后面会介绍)
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map
参考文献
1. https://blog.csdn.net/bitcarmanlee/article/details/82320853 ↩
2. 一个二维的向量 ↩
3. http://www.cnblogs.com/rgvb178/p/6055213.html ↩
4. https://blog.csdn.net/lwc5411117/article/details/83620184 ↩
