【摘 要】 这篇论文提出了一个新得图像增强神经网络,该网络学习的并不是图像到图像的映射,而是图像到增强图像中间的转换过程,学习的是仿射变换,再通过仿射变换生成增强图像,利用了自然光照具有明显先验的特点,颇具创新性。除此之外,还提供了一个新的数据集,该数据集拍摄了多种情况夜景共3000张,另外叫P图大师为每一张图片p正常光照的对应版本,壕无人性。
论文链接:Underexposed Photo Enhancement using Deep Illumination Estimation
一、介绍
在晚上由于曝光时间,和有限的光圈大小,手机拍出来的照片太不能看了。但是经过对纹理,色彩信息分析,发现图片的大部分信息都保存完好,只是人眼不便于观察,所以需要研究一种算法,将夜间拍摄到的图片进行增强。本文关注的主要是基于深度学习夜景图像增强。
二、相关工作
在这部分,分析前人做的相关工作,这里只提几个重要的,与本文有些关系的。
2.1 Retinex-based Methods
这个方法和本文的模型建立有着直接的关系,Retinex中认为人感知到某点的颜色和亮度并不仅仅取决于该点进入人眼的绝对光线,还和其周围的颜色和亮度有关。Retinex的模型是建立在以下基础上的:
- 真实世界是无颜色的,我们所感知的颜色是光与物质的相互作用的结果。我们见到的水是无色的,但是水膜—肥皂膜却是显现五彩缤纷,那是薄膜表面光干涉的结果;
- 每一颜色区域由给定波长的红、绿、蓝三原色构成的;
- 三原色决定了每个单位区域的颜色。Retinex 理论的基本内容是物体的颜色是由物体对长波(红)、中波(绿)和短波(蓝)光线的反射能力决定的,而不是由反射光强度的绝对值决定的;物体的色彩不受光照非均性的影响,具有一致性,即Retinex理论是以色感一致性(颜色恒常性)为基础的。如下图所示,观察者所看到的物体的图像S是由物体表面对入射光L反射得到的,反射率R由物体本身决定,不受入射光L变化。
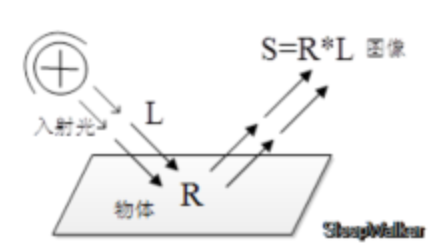
Retinex理论的基本假设是原始图像S是光照图像L和反射率图像R的乘积,即可表示为下式的形式:
这个公式在本文中颇为重要!!
2.2 深度学习模型
(说明可行性)
很多人使用了深度学习进行图像增强,效果非常优秀。但是大多数使用这种方法的人都是图像到图像的映射,在本文中,图像到光照图,光照图通过和原图计算得到结果图。因为光照图具有非常好的自然先验特性,比如平滑特征等。
三、算法模型
本文根据图像增强的常用算法,总结前人经验,拟用一种夜景-光照映射模型,模型的核心思想为:
其中$S$为光照映射图,$\bar I$为反射图,$I$为夜景图。此思想综合色彩、对比度、亮度以及纹理细节等多维特征,并将它们作为整体纳入模型中,避免出现因某一特征预测误差造成图像局部失真。
为什么这种模型能够工作?
把光照引入到网络中,本文需要训练网络完成图像到光照图的映射。这最主要的优点在于光照图像具有相对简单的形式和已知的先验特点。因此,该网络具有较强的泛化能力,能够有效地训练学习复杂的光照调整。此外,该模型还可以通过设置照明约束来定制增强结果。
四、网络结构
网络结构如下图所示,分别对不同的块的作用作解释。
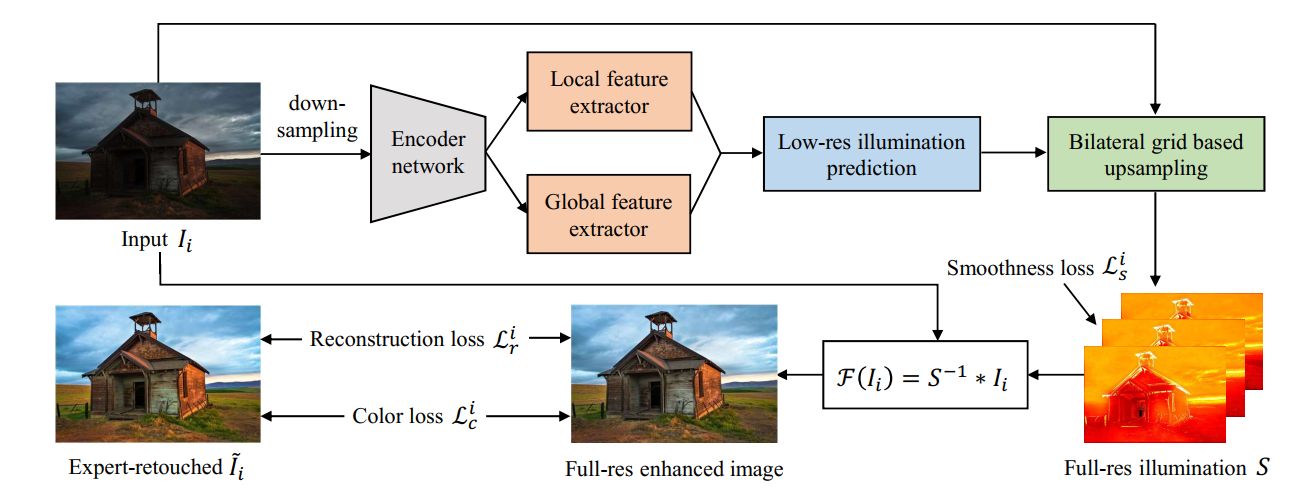
4.1 编码器
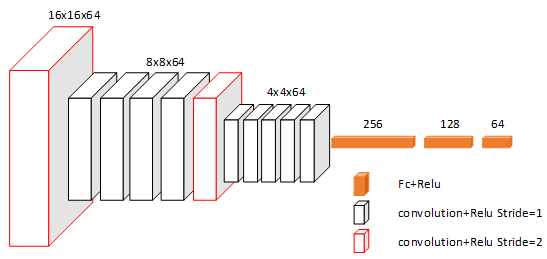
编码器在图像处理这块的表现相当优秀,图片在经过编码器之后缩小尺寸,不是真的缩小,可以理解为将原图拆分成很多小图。为什么要缩小,因为小图纹理特征更加明显,且处理速度更快!这种编码器网络在图像分割U-net、图像图模糊等领域都展现出了不俗的实力。所以本文中采用了编码器网络,在实际实现过程中,以VGG为模型,但是只有4层,图片每一层尺寸缩小一倍,输出维度为16x16x64。
4.2 特征提取
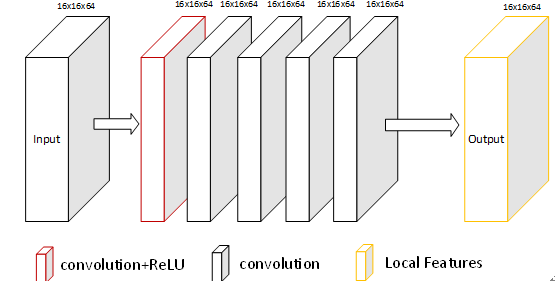
两路特征提取网络(局部特征提取和全局特征提取)都是深度卷积网络,每路的网络结构如下图所示。局部特征提取网络重点是对编码器输出的64个低分辨率特征图单个进行分析理解,这路网络输出维度和编码网络输出的维度一样为16x16x64。全局特征提取网络重点关注全局特征,对编码输出的64个低分辨率特征图整体分析理解,将数据整体分析融合后输出一维的64个数据。
4.3 特征融合预测
将全局特征和局部特征融合到一起生成16x16x64维度的特征,再将其输入一个卷积层中输出通道为96的特征,就算一个简单的统合操作。
4.4 双边网格上采样
双边网格上采样1网络,这是17年的一篇论文,原理不好解释。这里说下他的目的,处理一张高清原图对计算机算速度要求比较高,难以达到实时性。于是希望将原图降低分辨率进行处理,处理完之后在返回高清原图。这个返回过程就是双边网格上采样。
大致步骤是,将处理好的图片以原图进行参照进行恢复(别说,效果还是非常不错)。
输出一张和原图大小一样的光照图片。
最后的结果的输出是:原图除光照图,得到增强图片。轻松加easy。
五、损失函数
损失函数分为三个部分:平滑损失$L_r$、内容损失$L_s$和色彩损失$L_c$,其完整表达式如下:
内容损失:
色彩损失:
平滑损失:
内容损失表示输出图像和原图像的差距,色彩损失保证RGB的矢量方向一致,平滑损失根据光照先验,认为局部光照是平滑的。
六、代码调试日志
代码官方已经开源:点击跳转
- 环境:ubuntu
- 语言:python3.6(官方使用2.7版本,但我这里经过简单修改也能运行)
6.1 安装cuda和cudnn
这两个必须安装,否则会出现各种.so文件找不到,10版本以上应该都没有问题
6.2 安装运行环境
按照git中教程按照环境
6.3 问题1
TensorFlow安装目录不对,使用conda安装,但是没有安装在envs目录中,导致的问题是,import TensorFlow失败,解决方法,重新安装。
6.4 问题2
make 成功,但是运行程序,提示缺少符号,如下:
1 | undefined symbol: _ZTIN10tensorflow8OpKernelE. |
这种情况都是有都动态链接库没有找到对应的源文件造成的,说明在编译的时候少了文件,经过检查缺少:tensorflow_framework.so文件,在makefile文件的 CFLAGS 变量后面加上-ltensorflow_framework。
make 失败,提示找不到tensorflow_framework,这个时候需要添加这个文件的地址,地址目录可以使用TensorFlow提供的方法输出得到:
1 | import tensorflow as tf |
所以在makefile最前面添加:
1 | TF_LIB ?= `python -c 'import tensorflow as tf; print(tf.sysconfig.get_lib())'` |
在CFLAGS 变量后面加上:-L$(TF_LIB) -ltensorflow_framework
make 成功
6.4 问题3
运行代码,发现提示另外一个符号找不到:
1 | undefined symbol: _ZN10tensorflow8internal21CheckOpMessageBuilder9NewStringEv |
百度之后,将makefile中的D_GLIBCXX_USE_CXX11_ABI修改为1即可。如果是0,就换成1,是1就换成0。
最终makefile文件为:点击查看
6.5 问题4
代码开始跑,说明环境好了。但是由于python2.7和python3.6存在一些差异,还好只有两个地方,修改即可。
将run文件79行位置,改为:
1 | if not hasattr(models, str(model_params['model_name'], encoding="utf-8")): |
将run文件83行位置,改为:
1 | mdl = getattr(models, str(model_params['model_name'], encoding="utf-8")) |
成功运行。
七、输出
上图为输入图片,下图为输出图片。


八、总结
我觉得直接输出原图也是可以的,一个除法操作深度学习还是可以做到的。但是光照图的优势在于,我可以使用自然先验调整其平滑特性。
PS:我输出原图之后,在计算光照也行啊,如果这样的话,这就真的变成了端到端了~
参考文献
1. Deep Bilateral Learning for Real-Time Image Enhancement ↩
