一、前言
- 系统:win10
- 环境:python3.73
- 框架:torch
作为一个初学者,TSN的原始代码看的有点懵,代码注释太少了。这里以学习的角度,从熟悉torch框架开始复现TSN1算法。
二、相关原理介绍
TSN1是一种基于双流(Two Stream)模型2的姿态识别方法。在原有的网络模型上,通过修改输入数据的采样方式,在样本量少的情况下,高效的实现了长视频的姿态识别。
在介绍TSN之前,先介绍双流(Two Stream)模型2的大致原理。Two Stream在单网络(可以是resnet3、BNInception4)的基础上提出了双网络结构,采用两种不同的Input数据,分别输入到两个相同的网络之中,并且在处理过程中这两个网络互不相干,在最后将两个网络输出进行简单融合的处理。这两个不同的Input分别是:
TSN的改进部分,双流(Two Stream)模型的输入是使用的连续帧进行姿态识别,而连续帧之间的冗余信息其实很高,而且识别长视频的时候,对计算资源和内存空间开销很大。TSN改进了这种采集方法,将一个动作视频等间隔分为3个部分,在每个部分中随机提取数据(RGB,Optical Flow),这样由于中间跳过了很多帧,降低了计算资源的开销,就可以实现对长视频的动作识别,并且速度更快。准确率从实验结果上看,并没有明显下降。除此之外,TSN还提出了一些方法,扩展了有限的样本数量,使得学习的精度更高。
TSN的网络结构如下图1所示,主要分为了3个部分:
- Video(视频):将一个视频分为3个部分(segment)
- Snippet(片段):每个部分里面随机提取出一张RGB图像和一个Optical Flow或者RGB Diff信息。
- TSN网络:每个RGB图像单独使用一个空间网络(Spatial ConvNet),每个Optical Flow单独使用一个时间网络(Temporal ConvNet)。最后3个空间网络联合得到结果1(Segmental Consensus 绿色),时间网络联合得到结果2(Segmental Consensus 蓝色),结果1和结果2联合分析得到最终结果(Class Score Fusion)
在本文中,也按照这三个部分的顺序来进行复现TSN代码

根据图片,在实现过程中的误区指示:
- 3个空间网络内权值共享,3个时间网络内部权值共享
- 在每一个Snppet中,可以输入多个光流。一个光流由2张图片构成(x方向光流,y方向光流)
- Spatial ConvNet和Temporal的输出为图片的Lable,Segmental Consensus只是对3个网络做一个平均
- Class Score Fusion是对RGB、RGBDiff、FLow的输出做个平均。
三、数据集获取
这类视频数据集资源比较少,这里采用UCF101作为实验例子,实现以下功能:
- 分段随机提取RGB
- 分段随机提取光流
简单介绍一下UCF101数据集。
- 内含13320 个短视频
- 视频来源:YouTube
- 视频类别:101 种
- 主要包括这5大类动作 :人和物体交互,只有肢体动作,人与人交互,玩音乐器材,各类运动
- 视频格式:.avi
3.1 数据集下载
下载下载是一个zip压缩包,解压后里面是各种动作的视频,下载速度较慢,建议使用IDM下载,开32线程同步下载。联通4G网速,大概下载了40分钟。
需要下载两个,一个是数据,一个用来区分数据集和训练集的TXT文件。

TXT压缩包和文件内容的截图如下:
3.2 数据制作
根据7.5节数据集的制作原理,这里使用7.5方案一。为了得到TSN需要的训练数据,这里两个数据集
- 数据集一:又可以称原始数据集,仅仅返回视频地址,不对视频本身做任何处理。输入为数据集根目录地址,可提取到每个视频的地址和Lable。
- 数据集二:根据所需的数据,对每个视频进行处理,返回训练所需要的具体数据,如RGB,RGBDiff,Flow(光流)等需要的不同类型的数据。(这里只实现最简单的RGB作为例子,光流可以使用opencv内部的库实现)
这么设计的理由是为了降低内存的开销,如果一下把全部视频分解成帧写入到内存,对计算机内存消耗太高。现在使用这种方法,只有在参与训练的数据会写入到内存中。
3.2.1 数据集一设计
为了方便理解(加强我的记忆),把需要读取的7个文件列内容列出来。一个训练集对应一个测试集,有三组,每组训练测试集只是选取的数据不同,切不可把三个训练集和三个测试集全部同时读入。我使用的testlist01、trainlist01用作TSN复现。
classInd.txt、testlist01.txt、testlist02.txt、testlist03.txt、trainlist01.txt、trainlist02.txt、trainlist03.txt
- 输入:数据集地址、加载训练集还是测试集,默认训练集
- 输出:视频地址,lable
1 | from torch.utils import data |
最后的输出结果点击查看,现在已经可以很方便的获得视频的地址和lable
3.2.2 数据集二设计
这里用来输出对视频处理之后的数据
- 输入:数据集地址、训练集/测试集、所需数据类型、视频分段数等
- 输出:数据、Lable
代码说明:功能查看注释就好,以下对一些参数说明。
- weight、height:resnet101网络默认输入的图片尺寸为224*224,所以这里输出的图片尺寸就得跟着
- self.data:一张表,里面有视频的地址和Lable,依赖3.2.1数据集一
- __getitem__:核心部分,看代码建议从这里作为入口
- _Change_to_RGB:将视频随机抽帧,转为一组RGB图片
- _generate_random:生成随机数,不需要仔细看
- _Image_ReShape:修改图片的shape形状,不改变数据
1 | class myDataSet(data.Dataset): |
3.3 数据使用
对数据集的功能做一个简单的测试,输出数据集的size,并显示图片(因为图片的默认shape被修改,显示出来的单通道颜色比较奇怪),首先把数据集和数据集list文件放在一个路径下,就像这样:
在和上述代码同一个文件最下面,添加以下代码,并运行
1 | if __name__ == "__main__": |
输出结果:
1 | n_frames 56 |
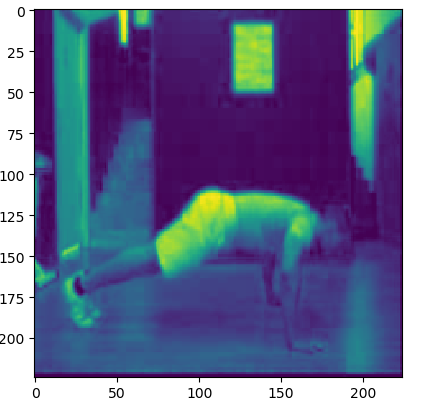
画重点了,仔细看这里将15张图片全部放在了一起,并没有分段,这是因为TSN网络里面看似是3个网络,但是这三个网络实际上是共享权重的,意味着其实只是一个网络。所以让一个网络同时学习15张图片,最后对loss进行一个求均值操作,完美。
3.4 总结
TSN作者写的源代码数据集制作方法如下,他在数据集和网络里都对图片数据进行了操作,代码互耦程度教高
- 提取全部帧保存(保存完后60多个G大小)
- 在数据集里提取对应图片
- 在网络里对图片进行差分
我的方法
- 提取全部视频地址和Lable。(无额外储存空间开销,总共大小6G)
- 在数据集里处理视频(转RGB,差分,光流),提取对应图片(差分和光流还没有做)
- 网络没有对数据集进行处理,纯粹只是训练网络功能
我的方法优缺点:
- 优点:没有额外储存空间,代码互耦低。不需要对视频进行预处理,方便实时监测视频动作。
- 缺点:在训练网络的时候还需要进行额外的视频操作,延长了训练时间
四、网络搭建
在开始学习的时候,使用的是mnist数据集来做3层的卷积网络,很方便自己搭建模型,这里有github例子可以参考8。但是如果面对100多层,并且是残差设计的深度学习网络,手动搭建起来就有点麻烦。Torch内部自带有一些常用的网络模型如resnet3,vgg等模型,使用的时候只需要进行加载,并且进行一些简单的修改。这里可能会有问题,为什么可以修改?哪里需要修改?
- 为什么可以修改?
答:输入数据的尺寸大小是对卷积层没有影响的,卷积层只对输入数据的维度感兴趣。只有全连接层对输入数据尺度有影响。
- 哪里需要修改?
答:根据上一个问题的回答。只需要对网络模型修改第一层卷积conv1的输入维度和全连接层对应的数据大小即可。注:对于mnist实验来说,第一层卷积输入维度是1,而在本次实验中,其值可能为2,4,10。
4.1 加载模型
torchvision库还有dataset等好用的东西,可以研究一下。以下代码粘贴复制即可直接使用。
1 | import torchvision.models |
为了方便理解,贴出obasemodel的打印,点击查看
4.2 修改模型
模型加载好了之后,有些并不能直接使用,可以对Conv2d的参数进行修改,一般来说,只需要修改维度值就好了,修改方法如下:(需要和上面代码联合使用)
1 | # 得到所有网络类型为Conv2d的下标,取第一个。前面有说为什么需要第一个 |
理论上这样就修改成功了,但是这里使用的是预训练的网络,更换了第一层网络后,其权重并没有跟着修改,接下来把权重也给复制上去,完整代码如下
1 | import torchvision.models |
修改成功,最后一层的修改方式和第一层的修改方式一样。注:kernel_size[:1] + (2, ) + kernel_size[2:]这种神奇的用法只适用于torch.Size类型。
4.3 TSN完整模型设计
TSN作者写的代码把三个网络写到一个Class里面,通过参数来选择不同的网络,虽然降低了代码冗余度,但是导致整个class太长,不方便阅读。这里我建立3个网络,方便阅读的同时,便于维护。
仔细查看TSN网络的构成,我发现TSN三种不同的输入对于网络部分(Temporal Segment Networks)来说是独立的!!意味着我可以单独实现RGB、RGBDiff、Optical Flow。光流算法需要依赖OpenCv库,这里在最后进行实现或者不实现,先从最简单的RGB开始。由于完全介绍的篇幅太长,转至Github上查看,有丰富的代码注释。
4.3 RGB网络
4.4 RGBDiff网络
4.5 Optical Flow网络
五、网络训练
训练相对较慢,需要动态调整学习速率 10
六、网络测试
在损失降低到一定程度后,开始测试。将训练模式转为测试模式即可。
七、语法小技巧
7.1 代码自动补全
python作为一门动态语言,在使用的过程中一般不需要注意变量类型。不过从实际使用角度上面来讲有点背道而驰了,因为变量类型必须要用到,但是在语法上面却没有了提示,这严重影响了写代码的体验(因为不知道类型,无法自动补全),以下提出一种方法,解决这个问题。(代码需要看前面的才看的懂,如果仅仅想了解如何指定类型,看参考文献7)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import torchvision.models
import torch.nn as nn
base_model = torchvision.models.resnet101(True)
# 这里因为使用了list,编辑器无法知道base_model里面参数的类型,必须要运行起来才知道
base_model = list(base_model.modules())
# 这里获取了第一个卷积的 index 下标
first_conv_idx = list(filter(lambda x: isinstance(base_model[x], nn.Conv2d), list(range(len(base_model)))))[0]
# 这里通过type指定类型,这样编辑器就会知道了,就可以自动补全了
conv = base_model[first_conv_idx] # type: nn.Conv2d
print(conv.kernel_size) # 舒服
7.2 list使用细节
list的会开辟新的储存空间
1 | a = [1,2,3,4] |
7.3 Torch.mean()用法
官方说明如下:
torch.mean(input, dim, keepdim=False, out=None)
返回新的张量,其中包含输入张量input指定维度dim中每行的平均值。
若keepdim值为True,则在输出张量中,除了被操作的dim维度值降为1,其它维度与输入张量input相同。否则,dim维度相当于被执行torch.squeeze()维度压缩操作,导致此维度消失,最终输出张量会比输入张量少一个维度。
参数:
- input (Tensor) - 输入张量
- dim (int) - 指定进行均值计算的维度
- keepdim (bool, optional) - 输出张量是否保持与输入张量有相同数量的维度,如果False,dim对应的那个维度消失,如果为True,dim对应的那个维度不会消失,大小变为1
- out (Tensor) - 结果张量
他的具体算法结构是什么样子呢?先举个例子
1 | import torch |
从输出结果可以看见,dim等于多少,那一个维度就会消失(计算成为了均值),这样他的内部算法就比较好猜了,应该是如下这样:
1 | b[][][] = (a[][0][][] + a[][1][][]) / 2 # 大致意思,应该运行不了,空括号内变量对应1,3,4维度不同值 |
其他max,min使用方法类似
7.4 torch.tensor.expand()用法
官方介绍
expand(*sizes)
返回tensor的一个新视图,单个维度扩大为更大的尺寸。 tensor也可以扩大为更高维,新增加的维度将附在前面。 扩大tensor不需要分配新内存,只是仅仅新建一个tensor的视图,其中通过将stride设为0,一维将会扩展位更高维。任何一个一维的在不分配新内存情况下可扩展为任意的数值。
参数: - sizes(torch.Size or int…)-需要扩展的大小
注意,只能对大小为1的那个维度进行扩展,扩展方法为复制原来的值,使用方法如下:
1 | a = torch.randn([1,2,3]).float() |
错误用法如下:
1 | a = torch.randn([1,2,3]).float() |
7.5 数据集制作
7.5.1 方法一
__getitem__是一个内建函数,它在什么时候被调用呢?下面用一个简单的例子来说明
1 | from torch.utils import data |
结果是:
1 | __init__ |
说明只有在进行读取数据集的时候__getitem__才会运行,在使用data.DataLoader的时候,不会调用。探寻这个有什么意义?
- 如果data.DataLoader会调用,那么只要使用了DataLoader函数,它就会将全部数据写入内存中,这种方法对计算机内存极为不友好。
- 如果是使用的时候调用,那么可以自定义__getitem__的实现方式,实现每次只读batch_size大小的数据进入内存。
注意:在DataLoader中,我设置了shuffle=True,但是输出结果并没有被打乱。查了资料后,发现它打乱的是__getitem__函数的item参数,修改代码如下,可以看到数据已经被打乱。
1 | from torch.utils import data |
输出结果:
1 | __init__ |
可以看到,数据被打乱。
7.5.2 方法二
使用TensorDataset实现对数据的封装,这种方法适用于比较简单的数据。其中enumerate是对数据加上index下边。
1 | from torch.utils import data |
输出结果为:
1 | index:0 |
八、调试问题
8.1 cuda runtime error (59)
在计算loss的时候出现的错误,原因是lable没有从0开始计数9。为什么非要从0开始计数,这要从误差函数的实现方式说起。为了方便理解,先抛出一个问题,看下面代码(运行正确的代码截断):
1 | # # output : torch.Size([3, 101]) |
可以误差函数criterion输出的output的size和OL的size不一样,不一样就不能直接计算,必须要经过处理。本人猜测,criterion内部先求出了output最大值对应的下标index(0~100),这样就变成了OL一样的size,这样就可以和OL进行计算(我测试过,不是求最大值),所以label的值的范围也是0~100。而数据集默认给的范围是1~101,故而由于数组越界而报错,严重甚至蓝屏(显卡出问题容易蓝屏)。解决方法,从数据集返回的lable下手,第三章数据集修改已更新。
接下来开始跟踪criterion内部的实现方式,我困了,下次弄
参考文献
1. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition ↩
2. Two-Stream Convolutional Networks for Action Recognition in Videos ↩
3. ResNet结构分析 ↩
4. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift ↩
5. 计算机视觉—光流法(optical flow)简介 ↩
6. 图像差分的方法 ↩
7. pyCharm中python对象的自动提示 ↩
8. torch 框架奇葩语法 ↩
9. cuda runtime error (59) ↩
10. pytorch学习笔记(十):learning rate decay(学习率衰减) ↩
